ML-Agents
Determinisitc Action


Deterministic Action
이번에 업데이트 되면서 Deterministic Action Selection 기능이 추가되었습니다. 학습하면서도 그리고 테스팅 (Inference) 하면서도 사용할 수 있습니다. 해당 기능이 업데이트 되지마자 RL_Korea Drone Delivery Challenge가 생각이 나서 바로 테스팅 해보았습니다. (어느정도 환경이 복잡하고 학습에 오랜시간이 걸리는 환경이 필요했기 때문입니다)
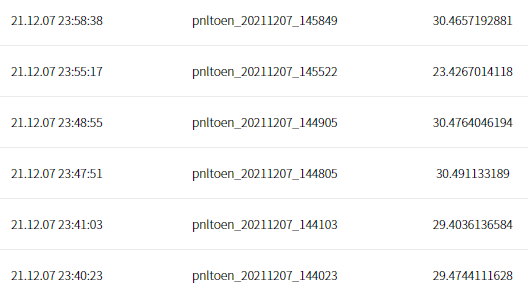
우선 AiFactory에서 챌린지 마지막 날 제출한 파일 내역을 보여드리겠습니다. 점수의 스펙트럼은 23.42~30.49까지 형성되어 있습니다. 여기서! 제가 제출한 파일은 모두 같은 .onnx 파일입니다! 조금더 쉽게 채점 메커니즘을 말씀드리면, 정수부는 배달 개수 소수부는 배달 완료 평균 시간을 뜻합니다.
이 점을 고려할 때 (소수부만 봐주세요) 0.40과 0.49는 대략 20%의 배달 성능차이가 난다고 생각할 수 있습니다.
이 뿐만 아니라 같은 파일인데 23점과 30점은 매우 유의미한 차이를 나타냅니다.
이러한 샘플링 문제 때문에 복잡한 챌린지 및 게임 환경에서 모델의 성능이 일관적이지 않았습니다.
하지만 이제 간편하게 콘솔 명령어에 --deterministic 또는 하이퍼 파라미터 설정에서 determinisitc: true를 추가함으로써 이러한 문제를 상당 부분 개선할 수 있습니다. 정확히 얼마나 개선되는지를 확인하기 위해 Inference 환경을 이용하여 확인해보았습니다. (Inference 환경을 제공해주신 RL_Korea에 감사의 말씀드립니다)
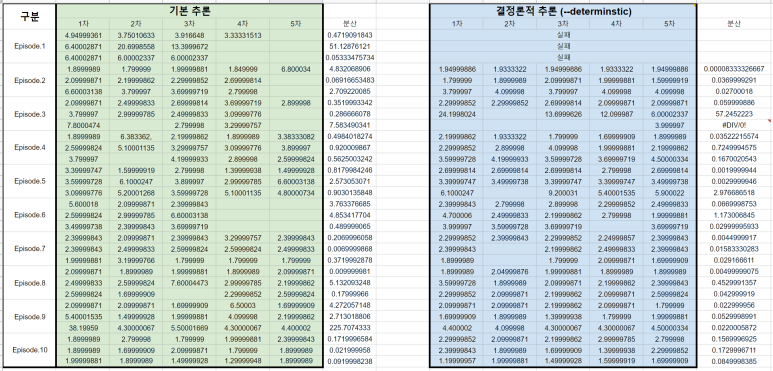
여기서 분산을 주목해주세요. 기본 추론 방법이 아닌 Deterministic 추론의 경우 한눈에 봐도 분산이 기본 추론에 비해 작은 것을 확인할 수 있습니다. 분산 값을 퍼센트로 확인해본 결과는 다음과 같습니다.
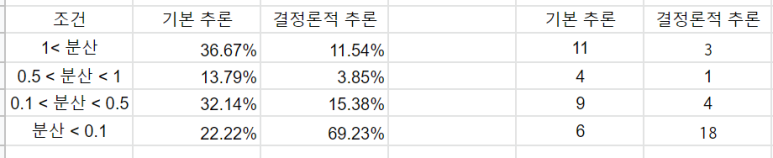
분산이 0.1을 기준으로 Deterministic 추론을 사용했을 때 퍼센트 비율이 3배가량 증가했습니다.
앞으로 이 기능을 활용해서 복잡한 게임, 챌린지에서 보다 일관적인 모델의 성능을 파악할 수 있을 것으로 기대됩니다!

댓글