RL Korea Drone Challenge 후기
대회 종료
대회가 끝난지... 2주가 지났다!
원래 대회가 종료되면 바로 후기를 작성하여, 뭐가 부족하였는지 체크하고 공부 계획을 작성할 예정이었으나...
기말고사 + 보고서 작성 + 공모전 + 미뤄왔던 방 정리 + 인턴 면접 + 개발환경 setup 등등 너무 많은 일이 있었어서 늦춰지게 되었다 ㅠ.ㅠ
주의 : 일기장 형식으로 작성된 글로, 자아성찰이 주된 이야기입니다.
챌린지 참여동기

휴먼러닝
단순 수상 보다는 정말 대회에 참가하면서 개인적으로 강화학습에 대한 공부 및 문제를 풀어보고 싶었다.
트렌드 측면
트렌드가 잘 반영된 챌린지였다고 생각한다. 현재 아마존에서 드론 배송을 하고있고, 이러한 트렌드에 맞춰서 현대자동차에서 현대자동차의 드론 강화학습 인턴 모집 공고를 진행하였다. 이러한 트렌드에 맞춰 단순하게 강화학습을 적용하는 것이 아닌, 실생활에 사용될 수 있는 환경을 갖고 챌린지를 진행한다는 점이 상당히 매력적으로 다가왔다.
정보 교류 및 내 위치 확인
본 전공이 기계공학으로써, 주변에서 강화학습 또는 시뮬레이션에 관한 정보 얻기가 쉽지 않았다. 또한 다른 사람들이 어떻게 문제를 구성하고, 해결하는지 그리고 나의 이러한 문제 풀이 능력이, 다른 사람들과 비교했을 때 어느정도 수준인지 확인하고 싶었다.
Drone Challenge 진행기
수상 목표 설정

수상 기준이 2가지로, ML-Agents 이용 또는 Python API를 이용 하는 방법이 있었다. 이 중 ML-Agents를 사용하는 방식이 나에게 가장 친근하였고, 다른 국방로봇경진대회, 교내 프로그램, 국가과제 일정 상 Python API를 이용하는 방식은 솔직히 부담감이 너무 컸다. 또한 Python API의 경우에는 데이터 전처리 등 사용자의 역량에 많은 차이가 발생한다고 생각하여, ML-Agents를 이용하여 특별상 수상을 목표로 진행하였다.
- 물론 Jorldy를 이용한 Python API 방식 또한 진행하였다. 다만 정해진 컴퓨터 갯수에서... 여러 방식을 사용한다는 점이 큰 제약이였고, 사실 이 부분은 경험 부족으로 인해 적절한 알고리즘, 접근법을 잘못 설정하여 사실상 맛보기만 한 것 같다.
하이퍼 파라미터 튜닝
ML-Agents 특별상을 받기 위해 내가 선택할 수 있는 알고리즘은 PPO와 SAC였다. 정말 다행스럽게도!!! Unity ML-Agents Github/docs/Learning-Environment-Examples.md에 보면 각각의 환경 그리고 환경에 맞는 하이퍼 파라미터 파일을 볼 수 있다. 따라서 철저하게 이러한 예제를 이용하기로 했고, 이번 Drone Challenge와 최대한 비슷한 환경이 무엇이 있을까? 그리고 어떤 하이퍼 파라미터를 값을 사용했는가? 마지막으로 동일한 환경에서 PPO와 SAC가 있는데 각각 하이퍼 파라미터가 얼마나 다른가?에 대해 논문 및 자료조사를 진행하고 학습을 진행하였다.
뒤돌아 보니 진행했던 접근법, 그리고 방식이 맘에 들지 않아... 현재 혼자 다시 진행하고 있다. 세부적인 내용은 추후에 충분한 검토시간을 거친 후 포스팅할 예정

문제점
환경 수정 불가능
기존 혼자 공부 및 환경을 제작할 때는 제대로 학습이 되지 않을 경우 바로 환경을 수정할 수 있었다. Raysensor 보상함수 로직 설계 등 내 입맞대로 수정이 가능하였는데 챌린지의 경우 빌드파일을 제공받음으로써 해당 수정이 불가능하였다. 예로 미션 수행 속도를 높이기 위해, 기존에는 환경에 타이머를 구현 후 초당 감점을 받는 방식으로 학습을 진행하였는데, 빌드 파일을 통한 ML-Agents는 환경 자체를 수정할 수 없었고, 이를 해결하기 위한 방법은 하이퍼 파라미터 튜닝 밖에 없다는 점이 크게 낯설었다.
학습 시간 문제
PPO 기준 정말 이게... 맞나...? 싶을 정도로 오래걸렸다. 초기 학습 단계에서 1개의 배달지에 도착하기 위해서는 하루의 학습 시간이 걸렸다. 고려해야할 수치적 관측이 약 95개로, 2의 배수인 64로 학습을 진행할 때는 너무 불안정하였고, 128로 진행했을 경우 너무 오래걸렸다. 생각해보니 굳이 2의 배수로 할 필요가 있었나... 싶다. 그냥 buffer size의 약수로만 진행하고 batch를 95로 설정해도 됐을 것 같은데... 너무 근시안 그리고 좁은 범위에서만 생각한게 문제였다...
학습 시간이 오래 걸리니 당연히 여러 모델을 테스트 하는 것에 제한을 받았다. 이를 해결하기 위해 교수님 찬스를 써서 학과 컴퓨터실 자체를 빌렸지만 CPU 성능이 너무 낮아, 연구실 또는 집에서 하는 속도의 70% 성능만 낼 수 있었다.

학습 시간이 오래 걸리니 당연하게도 랜덤성에 영향을 받는 강화학습 특성상 같은 파라미터로 학습을 진행하여도 학습이 안되는 결과가 발생하였다. 따라서 다시 튜닝한 하이퍼 파라미터를 통해 학습을 진행 후 학습이 되지 않았을 경우 이러한 하이퍼 파라미터 셋팅이 잘못된 것인가? 또는 학습이 됐을 경우 운이 좋은 경우인가...?에 대한 판단에 확신이 들지 않았다.
나만의 착각
팀원이 3일 째 30개 배달이 가능한 모델을 학습 완료하였다. 이 후 모델 평가 기준에 따라 어떻게 학습을 진행하면, 빠르게 배달이 가능한지에 대해 관점을 가졌어야 했다. 하지만 상을 받을 수 있겠지? 하는 착각에 빠져 하이퍼 파라미터 튜닝에 홀리게 되었다. 어떻게 튜닝을 해야 학습 시간을 단축시킬 수 있는지 새로운 도전을 진행하였다. 그 결과 불안정하지만 12시간에 3개 배달이 가능한 모델을 발견하였다. 많이 배웠으면 됐지 뭘...
경로 탐색의 어려움
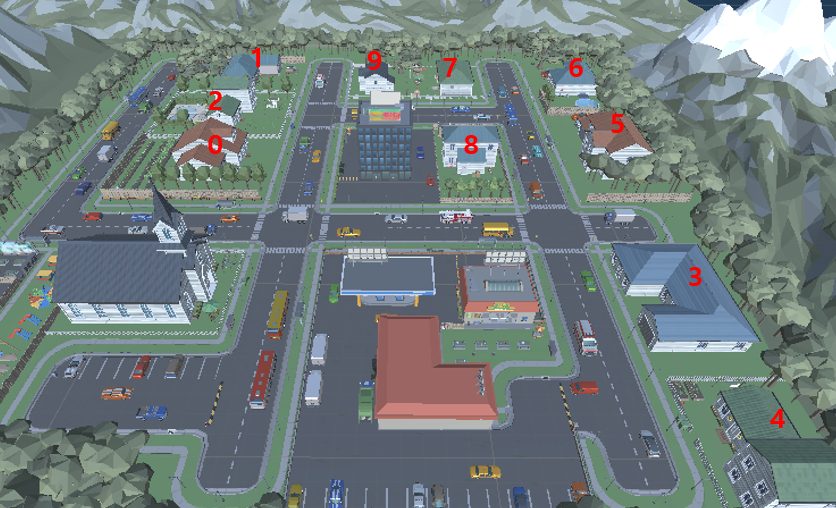
예로 집의 번호인 1,6,4가 목적지로 주어졌을 경우 학습이 매우 어려웠다. 최단 거리를 생각해보면 4-6-1로 학습을 진행하는 것이 가장 이상적이지만, 내 드론은 이러한 탐색에 취약했다. 극단적인 경우에는 1번을 도착하고 4번을 찍고 6번을 갔다가 다시 4번으로 돌아오고... 다시 6번에 갔다가 돌아오고 이러한 현상이 자주 나타났다
결론 및 고찰
수상에 실패하였다. Python API와 ML-Agents를 포함하여 7등 물론 해당 분야를 공부한지 반년도 채 되지 않았고, 200팀 그리고 다른 프로젝트를 진행하면서 7등이면 나쁘지 않은 성적(?)이라고는 절대 생각하지 않는다. 수상 커트라인이 30.5194855827점이였고 내가 30.4956420494로 4%의 차이였다. 이 4%의 차이를 무엇으로 극복할 수 있을까?를 대회가 끝난 후에도 계속 생각하였다.
대회기간에 자료조사를 하던 중 학습이 완료되었다고 가정했을 때 SAC가 PPO 보다 더 빨리 목적지에 나아간다는 포스팅을 보았고 SAC로 학습을 진행하였는데 모두 1개 밖에 배달을 하지 못하였다. 이 후 Drone Challenge에서 종합 1등을 하신 이현호님께서 올려주신 notion에서 그 이유를 찾을 수 있었다. (이현호님 Notion 링크) 너무 좋은 자료 공유해주셔서... 정말 감사합니다 ㅠㅠㅠㅠㅠㅠㅠㅠ
Discount Factor ML-Agents에서는 gamma를 나는 0.999 또는 0.9999로 진행하였는데 이는 rnd module를 사용해서 새로운 최단경로를 탐색하기 위함이였다. 하지만 내 의도와는 다르게 discount factor가 이전의 행동을 고려해서 오히려 땅에 추락해버리는 현상이 발생하였다. gamma 값을 조정함으로써 학습에는 더 속도가 붙었고 tensorboard를 통해 확인했을 때 오? 더 학습이 잘되네 라고 착각을 해버렸다. 결과적으로 드론의 negative action만 높이게 되었다. 이는 100% 개념 부족이다. 현재 볼만한 책은 다 구매하였고, 학습 계획도 잘 구성했으니 남은건 실천하는 일 뿐!
개인적으로 쌓아온 자료가 너무 아쉽다. Github에 하이퍼 파라미터 튜닝 관련해서 여러 모델을 만들었는데..... 내가 진짜 이 챌린지에만 정말 떳떳하게 모든걸 다 걸고 투자하지도 못했고 Unity 예제와 비교해보았을 때 내 개인적인 학습에 정말!!! 도움이 많이 되는 환경이라고 생각한다. 따라서 방학기간에 천천히 그리고 빠르게 정말 기본적인 개념부터 제대로 다시 학습을 진행할 예정이다.
ML-Agents로 SAC 30개 학습 진행 -> PPO 학습 모델과 비교 후 더 나은 알고리즘으로 30.51이상의 점수 받기
생각중인 여러 알고리즘을 Jorldy로 학습 진행 -> 알고리즘의 기본 개념 학습 및 학습 결과 예측 후 내가 예측한 대로 진행이 되는지 확인
위와 같이 진행중이다. 열심히 해야지!!!
마치며
챌린지를 진행하며 운영진 분들에게 정말... 너무 감사했다. 분위기도 너무 좋았고 비대면임에도 불구하고 RL_KOREA 운영진님들의 피드백이 정말 빠르고 섬세했다. 민규식님께서 질문 사항 그리고 빠른 피드백을 적극적으로 해주셔서 강화학습에 대한 개념 그리고 강화학습 자체는 아니지만 일을 처리하는 프로세스, 방식 등 많은 부분을 옅볼 수 있었다. 상세하게 이야기하면 거의 논문으로 작성해도 될 정도로 단순 챌린지 참여뿐만 아니라 정말 많은 것을 배울 수 있었다. 또한 1위를 하신 이현호님께서도 모든 코드 및 구상 방법을 공유해주심으로써 내가 생각한 방법 그리고 접근법과 비교 그리고 어떠한 부분이 부족했는지를 명확하게 짚을 수 있었고 앞으로 학습 가이드라인 및 어떻게 진행하면 되는지 정말 많은 도움을 받았다. 추가적으로 댓글로 Jorldy에 대한 내용 질의 응답, 메일로 질문도 받아주셔서 기존에 작성하신 논문의 구현 및 Agent 코드 등 정말 중요한 자료 및 이야기를 들을 수 있었다. 마지막으로 개발을 담당해주신 운영진분께서도 매번 댓글 달아주셔서 정말 힘이되고 기분 좋게 진행할 수 있었다.
그런 의미로 앞으로 더욱 화이팅하기!

댓글