Python Server
Unity Technologies
서문
유니티 Sentis에 TTS 관련해서 Jets 샘플이 있습니다. Jets의 경우... 사실 음성의 높낮이 정도만 조절하기 때문에 성능이 그다지 좋지는 않습니다.
unity/inference-engine-jets-text-to-speech · Hugging Face
Jets Text-to-Speech Model validated for Sentis 2.1.2 in Unity 6 This is a text to speech model called Jets. It takes in a text string which you convert to phonemes using a dictionary and then outputs a wav to play the voice. How to Use Create a new scene i
huggingface.co
Hugging Face 좀 찾아보다가 요즘 Kokoro-82M가 핫하길래 유니티에서 TTS를 다루는 샘플을 진행해보고자 하였습니다. 기본적으로 음성을 생성하거나 전처리 하는 부분은 Jets 구현 코드를 많이 찾아보았는데 Kokoro는 3rd party 라이브러리를 이용해서 텍스트를 전처리 (phoneme)하고 모델에 넣어주는 것으로 확인이 되네요...
hexgrad/Kokoro-82M · Hugging Face
Kokoro is an open-weight TTS model with 82 million parameters. Despite its lightweight architecture, it delivers comparable quality to larger models while being significantly faster and more cost-efficient. With Apache-licensed weights, Kokoro can be deplo
huggingface.co
예제 코드를 보면 영어의 경우 Misaki를 활용하고 phoneme 단위가 되지 않는 부분은 espeak를 활용하여 fallback 하는 것으로 보입니다.
# Misaki G2P with espeak-ng fallback
fallback = espeak.EspeakFallback(british=False)
g2p = en.G2P(trf=False, british=False, fallback=fallback)
한국어의 경우 공식 문서에서는 g2pk를 활용하라고 나오는데 공식 kokoro-82M에는 한국어 음성 학습 모델이 없어서 어차피 사용이 불가능합니다.
GitHub - Kyubyong/g2pK: g2pK: g2p module for Korean
g2pK: g2p module for Korean. Contribute to Kyubyong/g2pK development by creating an account on GitHub.
github.com
결과적으로 영어로라도 샘플을 만들어 보자 생각을 했는데 g2p가 발목을 잡네요. Misaki의 G2P 코드를 확인해보니... 이거 옮기는건 한세월 일 것 같습니다... numpy야 inference engine에서 대체한다고 해도 spacy는... 잘모르기도 하네요
misaki/misaki/en.py at main · hexgrad/misaki
G2P. Contribute to hexgrad/misaki development by creating an account on GitHub.
github.com
사실 유니티에서 Inference Engine을 사용하다보면 이미지는 Texture Converter로 해결이 되지만 문장의 경우... tokenizer, g2p 등 모델에 넣기 전에 여러 전처리가 필요한데 이걸 구현하는게 사실 쉽지 않습니다...
본문
그래서 가장 쉬운 파이썬 서버에서 전처리 후 유니티로 가져와 보려고 합니다... 사실 이 모델이 진짜 유니티에서 잘 작동하는지도 확인해야 하는데 import도 확실하지 않은 상태에서 전처리 로직 구현을 하는건 순서가 옳지 못한 것 같습니다.
flask로 파이썬 서버 만드는건... 너무 자료가 많아서 별도의 코드는 없습니다. 나중에 샘플로 공개할 예정
기본적으로 서버든 Json 관련 패키지든 처음 실행할 때는 성능을 많이 사용합니다.
대략적으로 처음 서버 실행할 때 40ms 정도 잡아 먹네요

실제 실행되고 있는 서버를 확인해보면 메모리는 309.6mb 잡아먹습니다. 이건 파이썬 안에서 라이브러리를 많이 써서 발생되는 문제로 보이고... 사실 c#으로 다 옮기는 것이 아니라면 해결이 어려울 것 같습니다.

newtonsoft의 경우 reponse를 받을 때 문자열의 공백을 삭제해버리는 문제가 있었습니다.
예를 들어서 python의 경우 다음의 결과를 얻었다면 유니티의 경우 각 문자간의 공백이 모두 삭제된 형태로 출력되었습니다.
Python: s ˈ u p ə ɹ h ˈ æ n s ə m s k ˈ I n ˌ ɪ m p ˈ I θ ˌ ɑ n s ˈ ɜ ɹ v ə ɹ w ˈ ɜ ɹ k s w ˈ ɛ lㅡ
Unity: sˈupəɹ hˈænsəm skˈInˌɪm pˈIθˌɑn sˈɜɹvəɹ wˈɜɹks wˈɛlㅡ
후처리는 유니티에서 진행하였고 결과는 다음과 같았습니다.
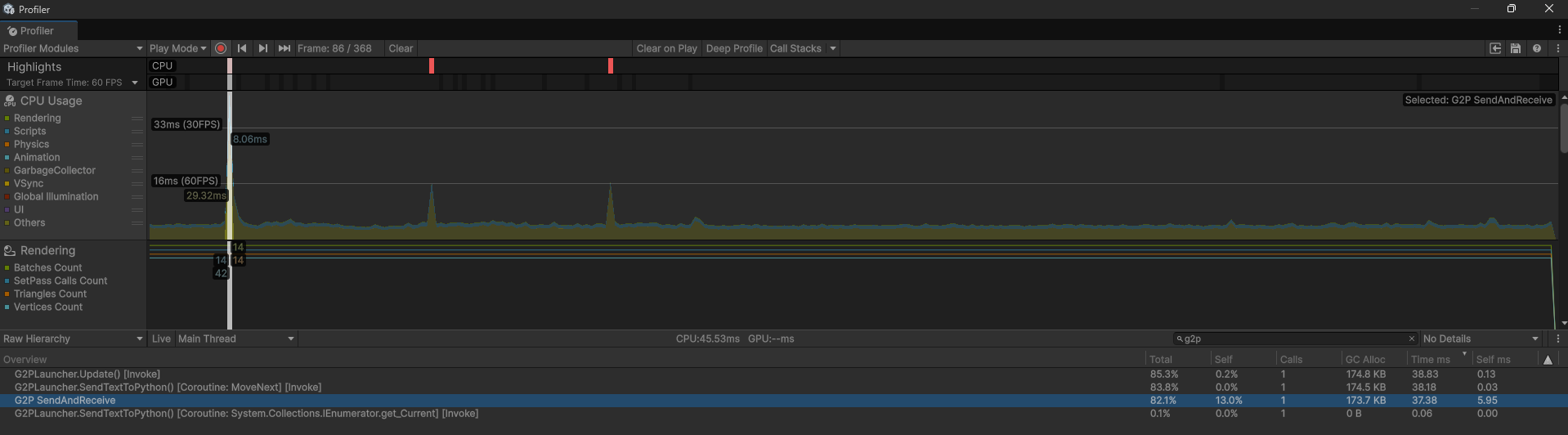
초기 실행시 대략 37.58ms (self 제외)
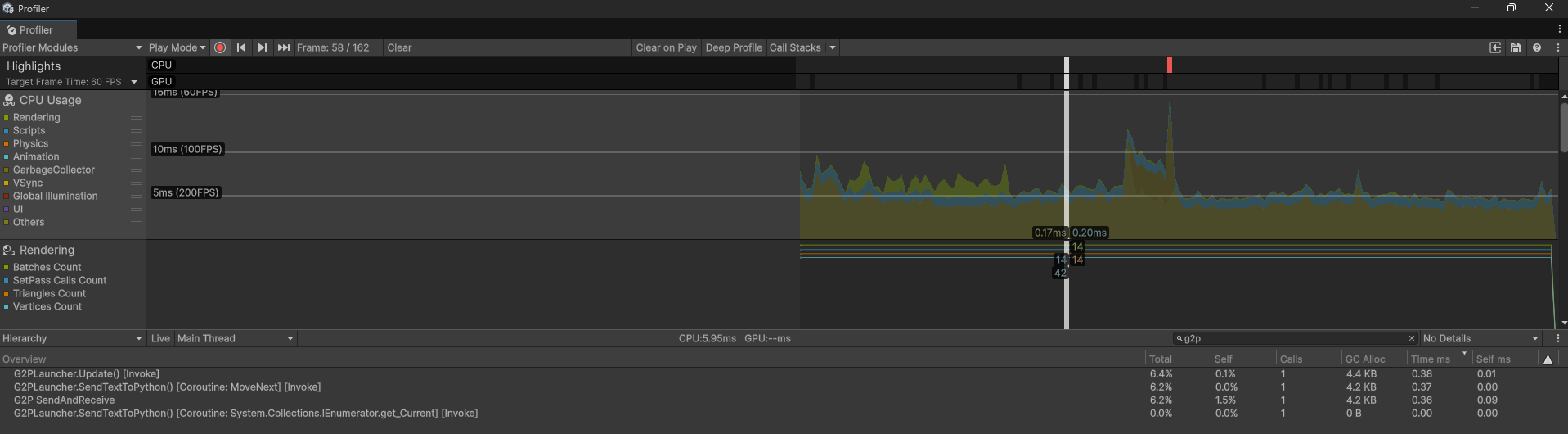
이 후 0.38ms로 실제 사용시에는 무리 없이 작동하는 것으로 확인하였습니다.
결론
빠르게 모델 작동 확인을 위해서 전처리가 문제일 때는 파이선 서버에서 받거나 아예 해당 데이터를 모델에 넣어서 진행하는 것이 좋다. 다만 이 경우에 Inference Engine (Sentis)의 장점인 On device 및 여러 플랫폼 빌드는 어렵다.

댓글