본 내용은 한국정보과학회 SWCC 2021 워크샵에 투고한 논문 중 일부임
보상함수 고찰 목표
강화학습은 최대보상을 갖는 기계학습기법으로써 나는 "보상의 최대화"를 양의 수로 인식하고 있었다.
이에 설계 단계에서 의도하지 않는 행동은 음수 그리고 유도하고 싶은 행동은 양수로 설정하였는데, 몇몇 상황에서 예상하지 못한 학습 결과가 나타났다.
자동차(에이전트)가 벽을 향해 달려가는 현상
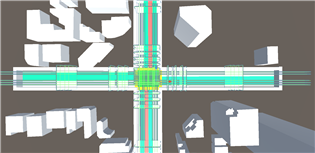
다음과 같이 환경을 만들었고 배경 건물을 제외한 흰색 벽과 에이전트가 충돌시 -1점의 감점을 주도록 하였다.
이 때 각각의 에이전트가 도착지에 도착하는 것을 유도하기 위해 각 체크포인트에 +1점부터 공차가 1씩 증가하도록 보상함수를 설계하였고 각각의 에이전트가 서로를 인식하고 피하기 위해 Raysensor 및 코드를 작성하였다.
이 때 시간이 지남에 따라 보상을 -0.001 그리고 에이전트가 서로 부딪힐 때 마다 -5점을 주니 학습 초기에는 교차로까지 진입하지만 교차로에서 차량끼리 부딪히는 경우가 너무 많이 발생해 체크포인트까지 진입했을 때 얻는 가점보다 교차로에서 차량 충돌로 받는 감점이 더 많아졌고, 이에 더 불어 시간에 따른 감점에 영향을 받아 차량들이 시작하자마자 벽을향해 달려가 -1.xxx의 감점을 받는 상황을 택하는 학습이 이루어졌다.
처음에는 보상함수를 잘못 설계했다는 것을 모르고 계속 에이전트가 벽에 부딪혀 게임을 끝나는 것을 보고 되게 의아했다. 분명 마이너스 보상을 받고 게임을 끝내는데 왜 벽을 향해 달려갈까? 결국이는 "보상의 최대화" 즉 강화학습에서는 음의 보상이여도 최대라고 생각할 경우 그 행동을 택하는 것을 확인하였다.
EndEpisode() 고찰
"그럼 벽을 부딪혔을 때 EndEpisode()를 호출하지 않으면 되는거 아닌가?"와 같은 의문점이 들 수 있다. 하지만 이는 유니티 물리엔진에 관련이 있다. 기존 500,000steps 의 학습이 너무 짧아 5억회 까지 횟수를 늘렸는데 그 결과 몇몇 상황에서 차가 벽에 껴 버리는 현상이 발생되었다.
분명 Agent의 Max steps 을 설정하였음에도 한번 끼기 시작하면 움직이지(step의 값이 올라가지 않는 듯) 않는 것으로 인식을 해 간편하게 벽을 쳤을 경우 에피소드가 끝나도록 설정하였다. 후에 더 좋은 방법이 있다면 개선이 필요할 것 같다.
콜라이더가 서로 밀치는 현상
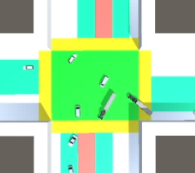
처음에 차량이 좌회전, 우회전 하는 것을 구현하려고 했고 여러 종류의 차량을 사용하고자 했다. 이후 학습을 시켜보니 버스가 중앙 교차로에 진입한 후 길을 찾기 위해 설정한 Discreteactions으로 움직이면서 주변 작은 소형차들을 무작위로 밀치는 것을 확인하였다. 처음에 봤을 때는 버스 3대가 회전을 하면서 차량들을 다 쳐냄으로써 다른 차들이 학습하는 것을 방해하였다. 위 사진은 버스를 2대로 줄였음에도 그대로 다른 차들의 진입을 방해하는 모습
예) 직진하던 차량을 우측 차선에서 박아 차량은 앞으로 가려고 하지만 우측 차선의 차 때문에 왼쪽으로 가고 그로 인하여 음의 보상을 받으면 차량은 이 감점 메커니즘을 1. 차가 박아서 감점을 받고 또 설정하지 않은 경로로가 2중으로 마이너스를 받는 것으로 인식하는지 아니면 2. 나는 앞으로 가는데 음의 보상을 받아 앞으로 가지 않으려고 하는지 이는 그 분에게 여쭤볼 예정
Suboptimal
진짜 Suboptimal을 너무 많이 봤다. 트리거를 설정해 차선 이탈 횟수 마다 감점을 주니 시작하자 마자 차선에서 벗어나 버리는 문제, 도착지점에 30개의 차량이 도착하면 에피소드를 종료하니 가로 또는 세로 한 차선을 막아버리고 하나의 차선만 이용해서 보상을 악용하는 문제 등 예상하지도 못한 기발한 문제가 많이 발생했는데 덕분에 재밌기도 하고 흥미도 많이 느꼈지만 고치느라 화났다... 이 부분에 대해서는 좀 체계적인 보상함수 설계법을 만들어야 할 것 같다.

댓글