유니티 코리아 공식 네이버 블로그에 정돈하여 작성하였습니다. 아래의 글을 참고해주세요. 본 글은 회고 및 정리 입니다.
Unity X G식백과 X ML-Agents (1) 셋팅
Unity X G식백과 X ML-Agents (1) 셋팅
Unity Unity X G식백과 X ML-Agents (1) 셋팅 개발의 민주화라는 유니티의 모토에 맞춰, 유니티를 ...
blog.naver.com
Unity X G식백과 X ML-Agents (2) QA적용 및 데이터 수집
Unity X G식백과 X ML-Agents (2) QA적용 및 데이터 수집
Unity Unity X G식백과 X ML-Agents (2) QA적용 및 데이터 수집 게임 업계의 관심이 머신러닝에 ...
blog.naver.com
Overview
하드웨어 사양 : I9 12900KF (CPU 사용)
학습 시간 : 2일 (1시간 부터 단순 클리어 가능, 이 후로는 안정화 및 탐색)
학습 스텝 : 6000만번 (단순 클리어 5M, 최종 40M)
작업 기간 : 2주간은 주말만, 저번 주 부터 평일에 서브로 진행
유니티 코리아 x 지식백과의 콜라보로 Gdori 튜토리얼이 제작되었다. 오지현 리드 어반젤리스트님께서 튜토리얼을 맡아주셨다. 뭔가 좋은 기여를 하고 싶고, 이전에 진행한 ML-Agents 활용 경험을 생각해봤을 때 충분히 ML-Agents 적용이 가능하다고 판단되어 프로젝트를 진행하게 되었다.
프로젝트 목표
본 프로젝트를 진행하면서 얻고자 하는 결과는 다음과 같습니다.
첫째, 실제 게임에서 강화학습을 적용하는 것이 매우 제한적인 것으로 알고 있는데 남들의 결과가 아닌 내가 직접 MDP 구성 및 환경을 수정해보고 실 게임에 적용할 때 강화학습이 어떠한 장점 및 제한점을 갖고 있는지 두 눈으로 직접 확인하고 싶었습니다.
둘째, ML-Agents 2.2.1이 업데이트 되면서 Determinisitc Action이 추가되었는데 1월 유니티 라이브에서는 Drone Challenge를 기준으로 성능을 확인하였지만 단순하게 목적지에 가까이 가는 것이 아닌 목표물을 피하고, 그때 그때 다른 상황을 하는 환경에서도 어느정도의 성능을 갖는지 알고 싶었습니다.
한 줄 요약하면... 휴먼러닝을 위해? (이 땐 얼마나 고된 길이 될지 몰랐었다..ㅎㅎ)
알고리즘 선정
+) 02.25 수정... 뭐에 홀렸었나 보네요... 새벽에 글을 작성했는데 다시보니 DDPG의 장점에 대해서 이야기 하면서 DQN 내용을 기술하였네요....ㅠㅠ 해당 부분 삭제조치 하였습니다 죄송합니다 ㅠ.ㅠ
게임 룰 변경 및 고찰
원활한 학습을 위하여 게임의 룰을 변경하였습니다. 우선 정말 잘 뽑히고 예쁜 Intro, Ending Cinematic이 있었지만 ㅠ.ㅠ 애니메이션 호출시 Control Disabled가 호출되어서 행동이 불가능하였고 학습이 진행되면서 해당 시간이 너무 길어질 것으로 판단되어 비활성화하였습니다. (마찬가지 이유로 VictoryZone.cs Player Entered Victory Zone.cs 전체 주석처리, PlayerEnteredDeathZone.cs 진입 시 게임 종료 및 재시작 하도록 수정)
기존 환경에서는 PlayerDeath가 호출 될 경우 Field의 Coin이 Respawn되지 않는 경우가 발생하였습니다. 이 코인(toekn)은 게임이 종료되여야만 재생성이 되었는데 초기 단계에서는 코인을 반영하였기 때문에 이러한 구현이 Nosie가 될 것으로 생각하고 PlayerDeath가 호출 될 경우 Coin이 Respawn 되도록 수정하였습니다.
=> 이 후 Coin 및 Playtime 보상함수 가중에 따라 학습 결과가 너무나도 달라져서 Coin을 모두 삭제하였습니다 (Std of Reward, 학습시간이 증대되었음, 따라서 보상함수 설계의 난이도 증가) 사실 코인을 없앨거였으면 EndEpisode() 및 OnEpisodeBegin() 메커니즘을 사용해도 됐을 텐데... 코인 때문에 코드 구현을 scenemanger.Loadscene()으로 진행하였음 ㅠ.ㅠ 관련 고찰은 유니티 ML-Agents Episode 종료 및 시작에 대한 고찰 글 참고!
코드 수정
음... 이 부분은 자세하게 기술하면 A4 30장도 넘게 나올 것 같아서... 감당이 안됩니다..ㅠㅠ 중요한 부분만 짚고 넘어가도록 하겠습니다.
일반적으로 PlayerController가 Mono가 아닌 Agent를 Inherit 하도록 바꿔주면 되지만 Gdori의 경우 PlayerController가 Kinematic Object를 Inherit 있기 때문에 Mono를 Inherit하는 Kinematic Object가 Agent를 상속하도록 변경하고 이 Kinematic Object(Agent)를 다시 PlayerController가 Inherit할 수 있도록 변경해주었습니다.
그 외에도 여러 코드 수정이 있는데 각각을 기술할 수 없기 때문에 수정한 파일의 리스트만 작성하였습니다.
|
Animation Controller.cs
|
Animator_Kinematic.cs
|
|
Death Zone.cs
|
Enemy Controller.cs
|
|
Enemy Death.cs
|
Gdori_Agent.cs(생성)
|
|
Health.cs
|
Kinematic Obejct.cs
|
|
Patrol Path.cs(선택)
|
Patrol Path.Mover.cs
|
|
Patrol Path Editor.cs
|
Platformer Jump Pad.cs
|
|
Platformer Model.cs
|
Platformer Speed Pad.cs
|
|
Player Death.cs
|
Player Enemy Collision.cs
|
|
Player Entered Death Zone.cs
|
Player Entered Victory Zone.cs
|
|
Player Jumped.cs
|
Player Landed.cs
|
|
Player Spawn.cs
|
Player Stop Jump.cs
|
|
Player Token Collision.cs
|
Token Instance.cs
|
|
Victory Zone.cs
|
이 외 프리팹 Tag, Layer 수정
|
단순 수정 및 참조 수정도 포함된 내역입니다. 아무래도 기본 Controller가 Mono가 아닌 Kinematic Obejct를 상속하다보니 Modified된 내역이 많지만 실제로 들어가보면 Gdori_Agent를 제외하면...ㅎㅎ 앗 그리고 Virtual 그리고 override에 대한 개념은 확실하게 알고 있어야 합니다.
기존 Kinematic Object가 virtual로 구현된 2개의 함수를 참조하고 있기 때문에 아니면 함수 실행이 안됨...! (이 부분에서 4일 넘게 날렸습니다 흑흑..ㅠ)
단순한 수정이기 때문에...ㅎㅎ (맞나...?)
MDP
MDP 설정함에 있어서 단순 경험도 경험이지만 참여했던 Drone Challenge 그리고 인프런 강의(유니티 머신러닝 에이전트 완정정복 -기초편)이 많은 도움이 되었습니다. 특히 Drone Challenge의 경우 MDP 설정에 대해 자세하게 작성되어 있으니 관심이 있다면 읽어보는 것이 좋습니다. 기초적인 지식만 있어도 공부하는데 많은 도움을 받을 수 있을듯..!
Observation
Drone Challenge의 난이도와 비교했을 때... Visual Observation은 필요하지 않을 것으로 예상, Vector Observation만을 사용하였습니다. 에이전트는 아래와 같은 상태 정보를 입력 받습니다.

목표 지점의 위치, 에이전트의 현재위치, 목표지점 - 에이전트 위치, 에이전트의 x축 속도, 에이전트의 y축 속도
(에이전트 x축 속도, y축 속도가 굳이 필요한가 싶어서 없애고 학습을 진행해보았는데, Inference해보니 확연히 Death Zone 진입이 많아지는 것을 확인할 수 있었습니다. 따라서 x,y축 속도 또한 사용)
에이전트의 센서는 지형을 감지하는 Level 센서와 Enemy 그리고 DeathZone을 감지하는 Enemy_Level 센서를 사용하였습니다. 에이전트가 직관적이고 Hierarchical하게 탐지하기 위해, Enemy와 DeathZone을 나눠주었습니다. 하지만 학습이 너무 오래걸리는 것 같아 둘을 Enemy Tag로 묶고 진행하였고 훨씬 나은 결과를 얻을 수 있었습니다.
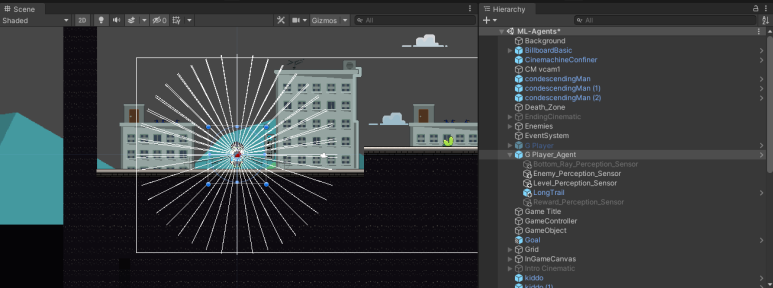
Ray Perception Sensor를 최소한의 개수, Rays Per Direction을 사용하기 위해 정말 많은 고민을 하였습니다. 학습을 진행해본 결과 Level의 경우는 110도로 설정하였습니다. 연직상방향을 기점으로 Ray를 생성한 이유는 에이전트가 걷는 것보다 뛰는 것이 더 빠르기 때문에 점프를 많이 택하면서 학습을 진행하였는데 이에 아래방향 보다는 윗 방향의 센서가 많이 필요할 것으로 판단하였습니다. 학습이 안되면 360도로 바꿔주려고 했는데 학습진행시 착지를 잘못하는 경우는 있어도 점프를 잘못하는 경우는 작아서 다음과 같이 셋팅하였습니다.
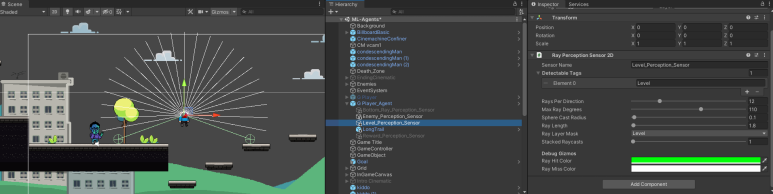
특히 여기서 점프하면서 Agent가 DeathZone에 진입하고 게임이 끝나는 경우가 많았습니다. 이를 해결하기 위해 Enemy Ray센서를 활용하였습니다.
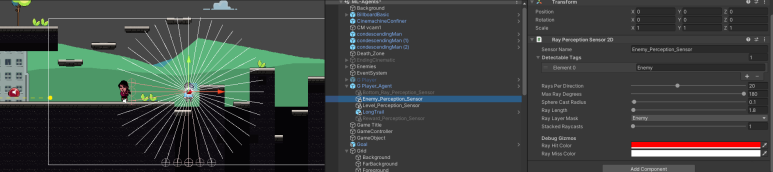
이 부분이 가장 에이전트가 학습하기 힘들어했고, 에디터 상에서 에이전트를 움직여가면서 적당한 Ray의 Length를 설정하였습니다. 1.8 정도면 에이전트가 점프하는 범위를 모두 커버할 수 있어서 점프전에 주변을 파악할 수 있다고 생각하였습니다.
Actions
에이전트 행동의 경우 최대한 기본 Logic을 살리는 방향으로 진행하였습니다.
public override void OnActionReceived(ActionBuffers actions)
{
actionX = actions.DiscreteActions[0];
actionY = actions.DiscreteActions[1];
}
public void OnactionX()
{
switch (actionX)
{
case 0: move.x = -1; break;
case 1: move.x = 1; break;
}
}
protected override void Update()
{
if (controlEnabled)
{
OnactionX();
switch (actionY)
{
case 0: bool_jumpDown = true; bool_jumpUp = false; break;
case 1: bool_jumpDown = false; bool_jumpUp = true; break;
}
if (jumpState == JumpState.Grounded && bool_jumpDown)
jumpState = JumpState.PrepareToJump;
else if (bool_jumpUp)
{
stopJump = true;
Schedule<PlayerStopJump>().player = this;
}
}
else
{
move.x = 0;
}
UpdateJumpState();
base.Update();
}| Step_Penalty | -0.015 |
빠른 클리어 유도
(-0.03과 -0.05 또한 해보았지만 너무 Negative해서 그런지 학습이 원활하게 진행되지 않음)
-0.001 또한 해보았지만 너무 Negative Weight가 작은 것 같아서 변경함
|
| Delta_Reward |
0.05 (목적지와 가까워질 경우)
-0.01 (목적지와 멀어질 경우)
|
Positive와 Negative Reward Value를 동률로 했을 때 어리버리 하는 현상 발생, 따라서 Positve의 가중치 조절함 |
| Goal_Reward | 10 | Episode 클리어 조건 |
| Death_Penalty | -10 | -5에서 -10으로 증가 |
| Kill_Reward | 0.1 => X | Enemy를 제거할 시 보상을 받도록 설계 이 후 Token과 함께 보상 삭제 |
| Coin_Reward | 0.02 | 가중치에 따라 에이전트 행동이 너무 달라짐, 빠른 학습 수렴을 위해 보상 삭제 |

Goal 코인과 접촉시 에피소드가 종료됨
Hyperparameter Tuning
목적지까지 여러 경로가 있음을 고려할 때 Rnd Module을 사용할 경우 학습 소요시간이 훨씬 늘어날 것으로 판단되어 단순 PPO 알고리즘으로 진행하였습니다. (Grid한 환경이기 때문에 Grid하게 탐색하는게 맞다고 판단)
하이퍼 파라미터 튜닝은 Drone Challenge에 사용한 값과 비교하여 진행하였습니다.
|
구분
|
최종값
|
시도 값
|
|
Batch_Size
|
64
|
16, 32
|
|
Buffer_Size
|
20480
|
2560, 5120, 10240. 40960
|
|
Learning_rate
|
0.001
|
0.003, 0.005, 0.01
|
|
beta
|
0.003
|
0.3, 0.05, 0.001
|
|
epsilon
|
0.2
|
0.1
|
|
lambd
|
0.95
|
0.8, 0.9, 0.95
|
|
num_epoch
|
5
|
2, 3
|
|
normalize
|
false
|
X
|
|
hidden_units
|
64
|
16, 32
|
|
num_layers
|
2
|
1
|
|
gamma
|
0.9
|
0.8, 0.85, 0.95, 0.99
|
Culmulative Reward를 볼 때 학습 전반적으로 모델 성능이 급격하게 하락하는 구간이 많았습니다. 따라서 최대한 안정적으로 학습을 진행하기 위해 Batch_Size를 16->32->64로 조정 및 Buffer_Size를 조절하였습니다. 지금까지 튜닝할 때 항상 Buffer를 Batch의 40배로 설정하여 사용하였고, --num-envs를 8로 설정하였기 때문에 64*40*8인 20480으로 설정하였습니다. 참고로 40960으로도 해봤는데 정말 너무 많이 걸려서..ㅠ.ㅠ 한 세월... (Learning Rate, Num_epoch도 동일한 이유로 조정함)
Beta의 경우 그렇게 많은 랜덤한 행동이 필요한가...? 싶어서 낮게 설정하였고 Continuous 한 action이 아니여서 normalize는 고려하지 않았습니다. 학습을 진행해보니 Actual Value 값에 더 의존하는 것이 좋다고 생각해 lambd를 0.95로 진행하였습니다. Hidden_Units은 Batch와 동일한 값으로 학습을 진행하였고 신경망 층수는 1로 했을 때 학습이 너무 불안정하여 2로 진행하였습니다.
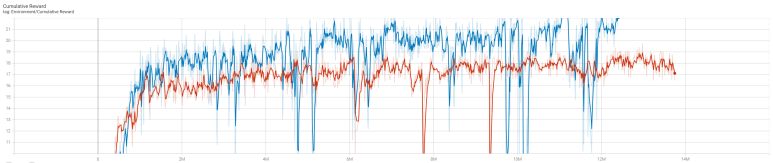
10M까지는 3번의 모델 성능 하락이 있었지만 위와 같이 기존 튜닝보다 훨씬 나아졌습니다. 10M 이후로는 별도의 모델 성능의 하락이 없고 Std of Rewards의 값도 줄어드는 추세입니다.
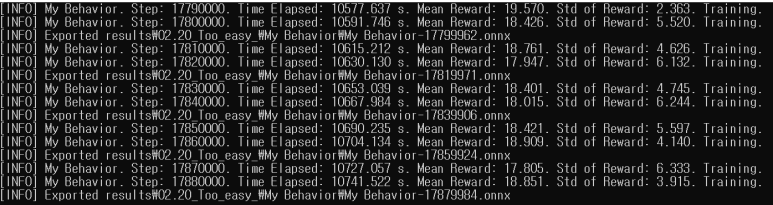
분산 값이 기존 7~8에서 2~6 사이로 줄어들었네요. 많이 안정화가 되는 추세인 것 같습니다.
Trained Model
Quality Assurance
강화학습을 통해 총 4가지의 버그(?)를 찾을 수 있었습니다.
Level Design
지형 디자인 Gdori가 죽지 않고 계속 벽에서 점프를 하는 현상을 발견하였는데, 벽에 낀 것인지 뭐가 문제인지 확인해본 결과 지형 디자인 (Collider) 문제임을 알 수 있었습니다.
Jump State
둘째 적의 머리를 밟을 경우 바운싱이 되어야 하는데, 바운싱이 아닌 오히려 빠르게 떨어지는 문제를 발견하였습니다. Heuristic에서 점프를 연타하니 재현이 가능했습니다. 그리고 셋째, 특정 상황에서 타이밍을 잘 맞출 경우 슈퍼점프가 되는 현상이 발생하였습니다. 해당버그는 재현이 불가능하였습니다.
해당 버그가 왜 일어났는지 디버깅해보니 적의 머리를 밟았을 때, Grounded 상태가 되어 즉 점프가 가능한 상태가 되어 점프하는 버그가 있었습니다.

Speed Pad
SpeedPad 진입시 점프를 잘 활용하면, 가속도를 받는 문제를 발견하였습니다.
전반적으로 JumpState 코딩에 대한 문제가 많았고, 따라서 JumpState에 Killing이라는 변수명을 추가하여, Enemy를 밟았을 때 점프를 하지 않도록 수정할 수 있었습니다. 지금 생각해보면 실 게임에서도 게임의 재미를 늘릴 수 있는 버그는 없애지 않는 것으로 알고 있는데 오히려 이전이 더 재밌는 것 같기도 합니다...ㅎ.ㅎ
고찰
머리속으로는 강화학습을 통해 에이전트가 무수한 행동을 하면서 버그를 찾을 수 있겠지...? 막연하게 생각만 하였는데 실제로 강화학습을 진행하면서 버그를 찾는 모습을 보고 되게 기분이 오묘했던 것 같습니다!
위의 4가지 버그를 대표적으로 찾을 수 있었고 에이전트가 어떻게 하면 빠르게 에피소드를 끝낼 수 있는지 탐색하고 그 과정을 Inference 하는 과정이 되게 재미있게 느껴졌던 것 같습니다. 다만 한가지 아쉬웠던 점은 버그라는 것이.... "누군가는 그럼 강화학습으로 QA를 하려면 학습의 초기 단계부터 후반까지 Inference를 해야 하는 것인가...?" 하는 생각도 들었고 제가 만약 강화학습으로 QA를 한다면 Curriculum Learning의 한 부분처럼 처음부터 게임에 적용하지 않고, 단순화된 환경에서 진행을 할 것 같다는 생각을 하였습니다.
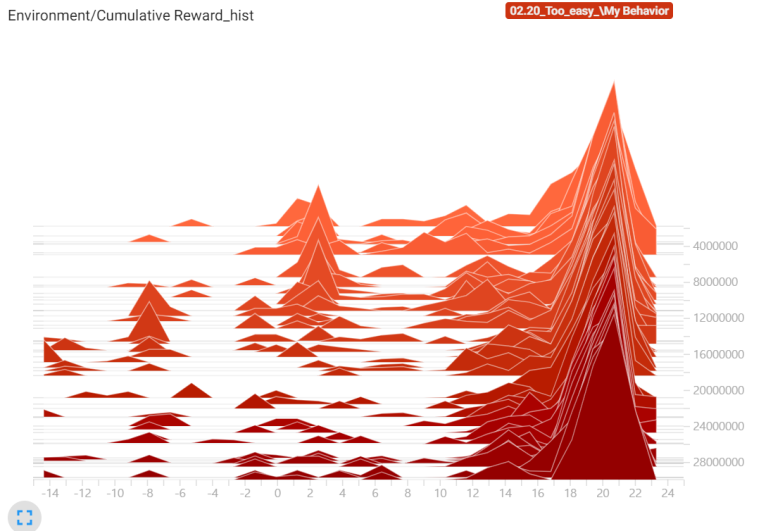
Histogram을 보니 확연하게 초기단계에서 에피소드가 종료되는 현상이 줄어들었고, Local에서 개인적으로 진행했을 때 이정도이면... 대형 게임회사에서 실제로 사용이 가능하겠구나...! 하는 생각이 들었습니다. 에이전트가 학습이 종료되는 즉 학습이 어려워하는 부분이 실제 게이머가 클리어 하기 어렵다고 느끼는 부분과 어느정도 일치할 것으로 생각하고 이러한 데이터를 뽑을 수 있다는 것도 강화학습의 큰 장점이라고 생각합니다.
+) Deterministic Action을 Enable하고 진행해보았는데... 생각과 너무 다른 결과가 나와서 남깁니다.
DroneChallenge의 경우 이 기능을 사용하면 확연하게 모델의 안정성이 높아졌는데 Gdori의 경우 모델의 성능(클리어 확률)은 똑같고 다만 클리어 경로가 일관성있게 선택되었음. 실제 모델의 성능에는 영향이 전혀 없었는데 Gdori가 Drone 환경보다 길어서 그런지... 한번 여러 방면으로 진행해봐야할 것 같습니다 ㅠ.ㅠ
노력
언젠가 추억이 되겠지...하고 쓰는 부분...! 하이퍼 파라미터 튜닝 횟수는 세본적이 없어서... 빌드한 횟수만 기록해본다. Main 컴퓨터 기준 58번의 빌드 진행, 본문에 적힌 내용 및 버그 픽스를 위해 여러가지 진행해보았다. 끝나고 보니까 되게 뿌듯한 느낌...!

댓글